Огляд алгоритмів та моделей машинного навчання в рамках технології штучного інтелекту (ШІ) та проблеми запровадження ШІ на підприємстві
Штучний інтелект набирає популярності та розвиває свої можливості. Останні роки особливої популярності набирають чат-боти на основі штучного інтелекту, як наприклад ChatGPT. В основі штучного інтелекту лежать потужні моделі та алгоритми які базуються на машинному навчанні. В роботі ми розглядаємо схему взаємозв’язку ШІ, машинного навчання та моделей (алгоритмів) нейронних мереж. Також, ми окреслюємо проблеми які можуть виникнути при впровадженні ШІ на підприємстві.
Останні роки в інформаційній спільноті неймовірно зріс попит на чат-боти зі штучним інтелектом та, загалом, тематика “штучного інтелекту”, “машинного навчання” лідирує серед перспективних напрямків подальшого розвитку інформаційного середовища. В 2023-му Словник Collins назвав “штучний інтелект” словом року та, наприклад, українські ЗМІ згадували ШІ – 167452 рази [6], тобто, дана тематика зараз є мейнстрімом та маркером інновацій. У Google, відзначили, що всього за рік, з моменту запуску, популярність ШІ стрімко зросла, причому, у певних регіонах світу вона помітно виділяється (лідирує у використанні даних технологій – Китай з піковим показником 100 балів, за ним йдуть Філіппіни та Непал). Зокрема, дані, зібрані компанією Finbold, свідчать про рекордний сплеск глобальних пошукових запитів у Google за терміном “ChatGPT”, який в листопаді 2023 року досягнув піку популярності у 100 балів та є лідером галузі від компанії OpenAI. Протягом 2023 року популярність чат-бота зросла на вражаючі 400%. А попит на ChatGPT у пошуку Google астрономічно зріс на понад 9000%.
Перший комп’ютер з прототипом ШІ було випущено в 50-х роках 20ст. З початку свого застосування комп’ютери використовувалися для задач, алгоритм вирішення яких був відомий людині. І тільки останніми роками прийшло розуміння, що вони можуть знаходити спосіб вирішувати завдання, для яких алгоритму рішення немає або він не відомий людині. Так з’явився штучний інтелект у широкому значенні та технології машинного навчання зокрема.
Штучний інтелект (ШІ) у найширшому розумінні — це інтелект, який демонструють машини, зокрема комп’ютерні системи, на відміну від природного інтелекту живих істот. Машинне навчання (МН) — це концепція, згідно з якою комп’ютерна програма може навчатися та адаптуватися до нових даних без втручання людини. Машинне навчання – це сфера штучного інтелекту (ШІ), яка підтримує актуальність вбудованих алгоритмів комп’ютера незалежно від змін у світовій економіці.
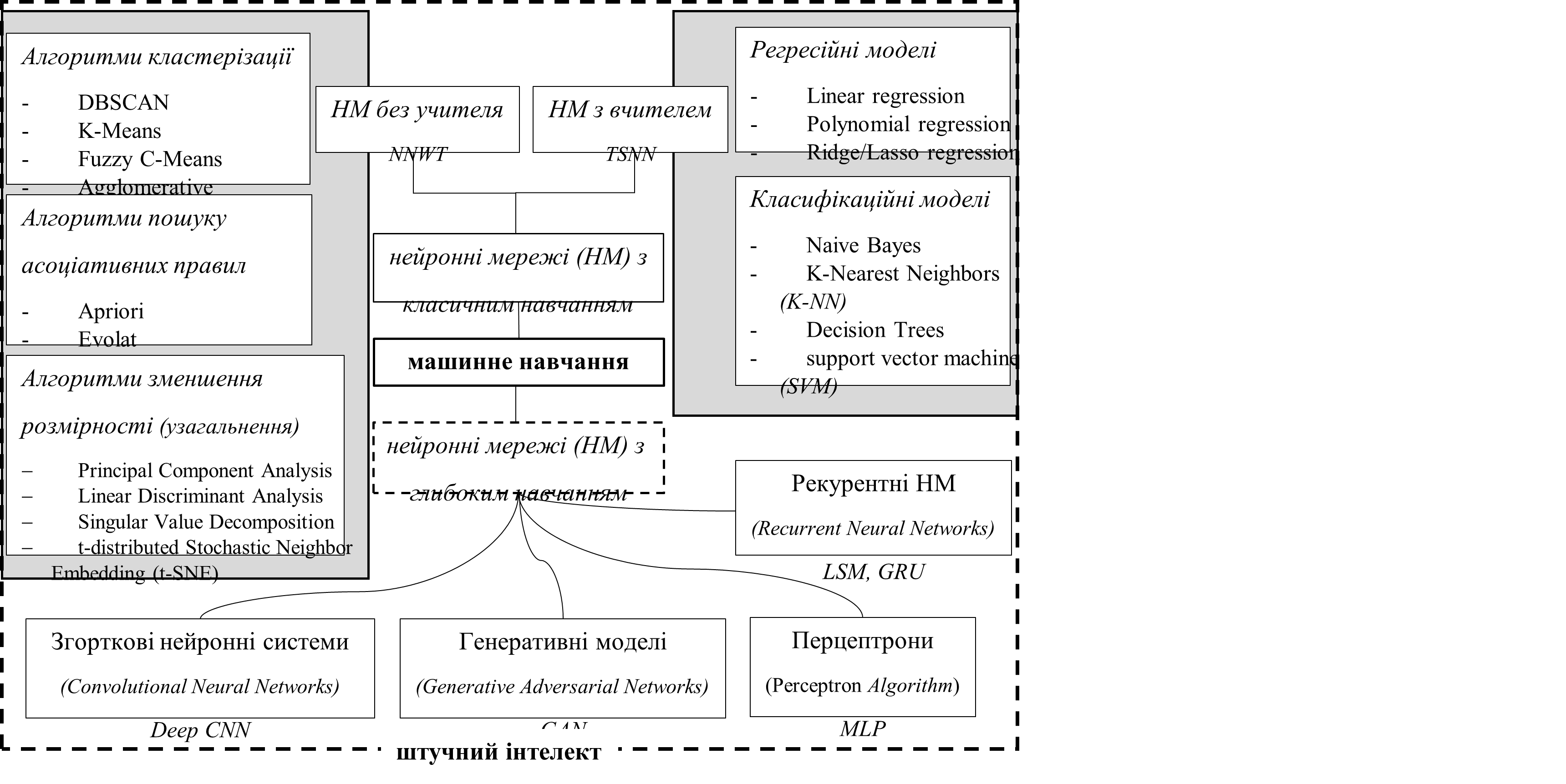
Нейронна мережа (НМ) — це програма або модель машинного навчання, що приймає рішення подібно до людського мозку, використовуючи процеси, які імітують те, як біологічні нейрони працюють разом, щоб ідентифікувати явища, зважувати варіанти та робити висновки. [3] На схемі нижче зображено взаємозв’язок ШІ, МН та НМ з прикладами алгоритмів та моделей що застосовуються.
Ажіотаж навколо ШІ не стихає, і як результат, багато компаній уже впроваджують та використовують його у своїй роботі, адже для випередження конкурентів та досягання успіху бізнесу, необхідне постійне удосконалення та розвиток застосовуваних технологій та інновацій. Проте на етапі впровадження ШІ у діяльність уже існуючого бізнесу може виникати низка проблем.
Першою і, напевно, найочевиднішою проблемою застосування ШІ є брак даних. Практично всі алгоритми машинного навчання вимагають великих обсягів даних, перш ніж почнуть давати корисні результати. Якщо ви погано “годуєте” модель у процесі навчання та калібрування, це дасть лише погані результати. До цієї проблеми можна віднести як брак даних (недостатня вибірка або статистичне охоплення) так і брак достовірних даних. Наприклад, нейронні мережі – це data-eating машини, які потребують великої кількості навчальних даних. Чим більша архітектура, тим більше даних потрібно для отримання життєздатних результатів.
Наступною проблемою є детермінованість систем та складність інтерпретації. Машинне навчання є стохастичним, а не детермінованим. Наприклад, НМ не сприймають закони фізики (тобто не мають певних обмежень), хоча в останні роки є ряд досліджень, які розглядають додавання фізичних обмежень. Інтерпретованість є першорядною якістю, якої мають досягти методи машинного навчання, коли вони застосовуватимуться на практиці. Якщо ви не можете переконати свого клієнта в тому, що ви розумієте, як алгоритм прийшов до рішення, яке він прийняв, наскільки ймовірно, що клієнт довірятиме вам і вашому досвіду. До цієї проблеми можна також віднести високі вимоги до професіоналізму майбутніх фахівців команди підприємства, які будуть досконало володіти алгоритмами машинного навчання та інтерпретувати всі кроки та результати роботи ШІ.
Третьою проблемою є зважене розуміння щодо доцільності використання машинного навчання в майбутньому проекті та етика, адже не завжди економічно доцільно використовувати МН (навчання просто не потрібне, не має сенсу, коли реалізація може призвести до труднощів). Якщо, наприклад, у нас «невелика» вибірка даних, ми можемо використати класичні, багатовимірні статистичні методи, які будуть набагато інформативніші. Щодо етики, то ми маємо завжди знати, які саме можливості створеного ШІ та, що ще важливіше, які його обмеження.
Література
- Ashish K. R. Dimensionality Reduction Algorithms in Machine Learning: A Theoretical and Experimental Comparison, 2023. https://doi.org/10.3390/engproc2023059082
- https://www.leverege.com/blogpost/machine-learning-naive-bayes-neural-networks
- https://www.ibm.com/topics/neural-networks
- https://towardsdatascience.com/perceptron-learning-algorithm
- https://machinelearningmastery.com/what-are-generative-adversarial-networks-gans/
- https://cpc.com.ua/articles/shtuchniy-intelekt-v-ukraini-dosvid-vikoristannya-perspektivi-trendi-v-media