АЛГОРИТМ ОЦІНКИ КРЕДИТНОГО РИЗИКУ ПОЗИЧАЛЬНИКІВ – ФІЗИЧНИХ ОСІБ З ВИКОРИСТАННЯМ МЕТОДІВ МАШИННОГО НАВЧАННЯ
Філатов В.Ю.
аспірант
Національний університет «Києво-Могилянська академія» (Україна)
Кредитний ризик – це основний вид ризику для банківської системи. Зокрема, банки України станом на 2020 рік розраховують рівень резервів тільки для цього виду ризику. В той же час, методи оцінки кредитного ризику в розрізі банківської системи дуже гетерогенні. Переважно банки з іноземним капіталом використовують досить складні моделі, але часто вони не відкалібровані на українських даних. Банки ж з українським приватним капіталом використовують більш прості моделі, але які розроблені відносно українських реалій. І в першому і другому випадку може бути як високий рівень точності розпізнавання дефолтних позичальників, так і низька.
Актуальність даної роботи росте разом з сегментом кредитування фізичних осіб протягом останніх років. На рис. 7 зображені суми нових кредитів за місяць.
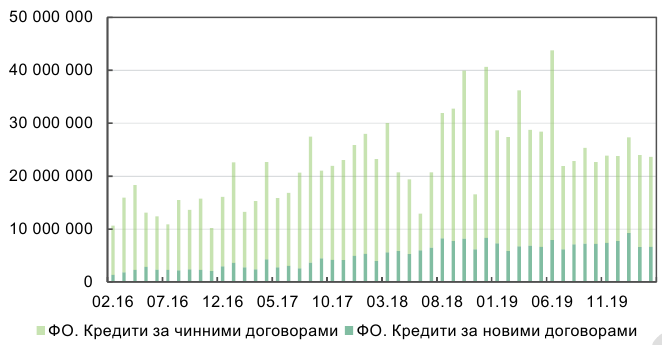
Рис. 7: Нові кредити для фізичних осіб (тис. грн)
Особливу увагу викликає постійне зростання кредитів за новими договорами. Це означає, що банки активно розширюють свій портфель за рахунок нових клієнтів, в той же час, накопичуючи системні ризики. По-перше, про сегмент нових позичальників банк ще немає достатньо даних, в тому числі даних про їх поведінку під час кризи. А по-друге, розширення бази клієнтів відбувається в більшості випадків за рахунок зменшення вимог до кредиторів. Починаючи з кінця 2015 року, банки системно знижують стандарти схвалення заявок на кредити для фізичних осіб.[1]
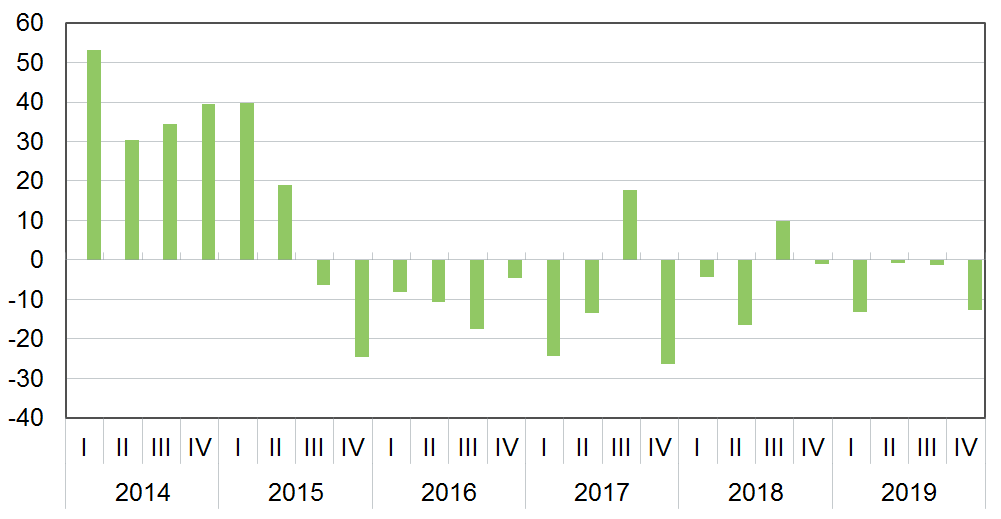
Рис. 8: Питання: «Як змінилися стандарти схвалення заявок на кредити домогосподарствам протягом кварталу, що закінчився?» (від -100 до +100)
З огляду на це, в роботі запропоновано розробити модель, на основі Кредитного реєстру, яка буде з високою точністю прогнозувати вірогідність дефолту для позичальників-фізичних осіб з кредитним портфелем більше 400 000 грн. Цей сегмент повністю представлений в Кредитному реєстрі, тому є наявною інформація про всіх позичальників в України в цьому сегменті. Отже дана вибірка є найбільш репрезентативною, а використовувані алгоритми машинного навчання дають кращі результати прогнозу, ніж стандартні підходи, такі як logit/probit моделі.
Кредитний реєстр включає в себе широкий спектр інформації про боржника, про стан кредиту і про стан застави. Вибірка складається з наступних змінних: вік, країна народження, кількість днів прострочення, валюта кредиту, сума кредиту, офіційний дохід, неофіційний дохід, періодичність платежу, тривалість кредиту, тип застави, вартість застави, клас боржника (від 1 до 5/від кращого до гіршого) і т.д.
Етапи формування моделі:
Складання переліку всіх релевантних методів машинного навчання.
Для аналізу використовуються Gradient boosting decision trees (GBDT), Light gradient boosting machine (LightGBM), Random forrest, Extreme gradient boosting (XGBoost), Quantitative Input Influence (QII), Artificial neural networks, Suppes-Bayes Causal Networks (SBCNs), Latent Dirichlet allocation (LDA), Support Vector Machines (SVM). Це найбільш популярні методи як в світових роботах, так і в роботах українських дослідників [2].
На основі мітки дефолт/не дефолт створення бінарної змінної («dummy variable») – залежної змінної в моделі.
Поділ вибірки даних на тренувальну вибірку і тестову вибірку.
Тестування всіх можливих комбінацій змінних для найкращого прогнозування дефолту на тренувальній вибірці.
Для тестування прогнозної здатності використовується AUROC (Area Under the Receiver Operating Characteristics) метрика [3], що показує, наскільки часто наша модель виявляє справжні дефолти, при цьому має відносно не великий відсоток помилкових прогнозів. Тобто навіть якщо модель з досить високою ймовірністю передбачує справжній дефолт, вона може часто «маркувати» дефолтним позичальника, який таким не є.
Тестування найкращих комбінацій тренувальної вибірки на тестовій вибірці.
Додатково: Для покращення прогнозної здатності використання методу головних компонентів (Principal component analysis) [4]. Його перевага в тому, що він значно покращує прогнозну здатність. Головний недолік в тому, що інтерпретація результату стає набагато складнішою. Це в свою чергу зменшує його привабливість для застосування в регуляторних цілях.
Як результати моделювання можна використати в регуляторній політиці Національного банку України: Національний банк може оцінювати вплив кожного фактору на вірогідність дефолту. Якщо умовний вплив буде зростати (або спадати) з часом, це може бути використано для макропруденційних рішень. Наприклад, якщо коефіцієнт для фактору «дохід боржника» почав мати більший вплив на вірогідність дефолту боржника – це може бути підставою для затвердження мінімального DSTI (Debt service to income ratio), LTV (Loan to value) тощо.
ЛІТЕРАТУРА
- НБУ. Опитування про умови банківського кредитування, І квартал 2020 року.
- Покідін, Дмитро (2015). Економетрична модель національного банку україни для оцінки кредитного ризику банку та альтернативний метод опорних векторів. Вісник Національного банку України №234.
- Fawcett, T. (2006). An introduction to ROC analysis. Pattern recognition letters, 27(8), 861-874.
- Wold, S., Esbensen, K., & Geladi, P. (1987). Principal component analysis. Chemometrics and intelligent laboratory systems, 2(1-3), 37-52.